前言
DeepLab系列论文一共有四篇,分别为:
一点一点加油~
DeepLab V1
DCNNs因为具有很好的平移不变性(空间信息细节已被高度抽象化)能够很好的处理图像分类问题,但是DCNNs的最后一层的输出不足以准确的定位物体进行像素级分类。DeepLab V1通过将最终DCNN层的输出与完全连接的条件随机场(CRF)结合起来,克服了DCNNs平移不变性的问题。
DCNNs有两个问题需要处理:
- 池化和下采样多次,导致分辨率下降,空间位置信息难以恢复
- 高层特征具有空间不变性,且细节信息丢失严重
解决方案:
- 减少下采样次数,保证特征图的分辨率,同时使用空洞卷积,扩大感受野,获取更多的上下文信息
- DeepLab采用完全连接的条件随机场(CRF)提高模型捕获细节的能力。
DeepLab V1是基于VGG16网络改写的,一共做了三件事。
- 将全连接层改为卷积层;
- 将最后最后两个池化的步长改为1(保证特征图的分辨率,只下采样8倍)
- 把VGG16中最后三个卷积层(conv5_1、conv5_2、conv5_3)的采样率设置为2,且第一个全连接层的dilate rate设置为4(保持感受野)
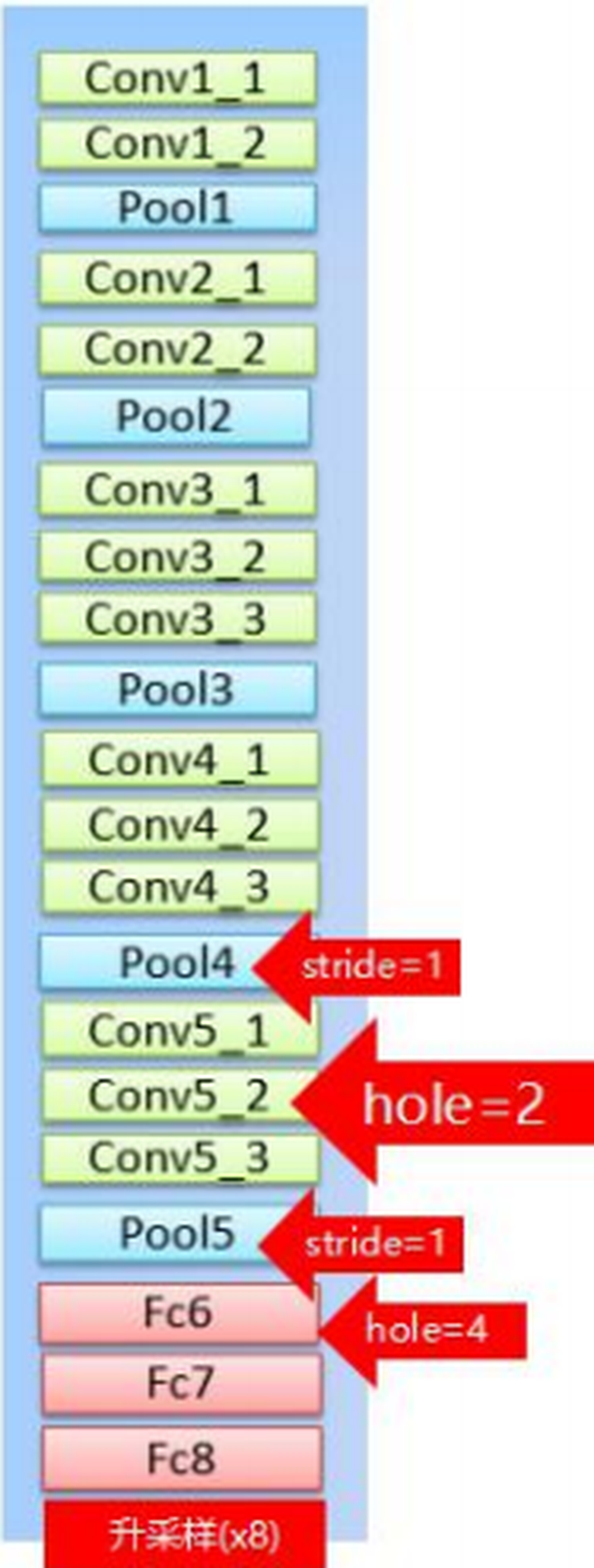
池化层作用:缩小特征图的尺寸;快速扩大感受野。
为什么要扩大感受野呢?为了利用更多的上下文信息进行分析。既然pooling这么好用,为什么要去掉俩呢?这个问题需要从头捋。先说传统(早期)DCNN,主要用来解决图片的分类问题,举个栗子,对于分类任务,传统模型只需要指出图片是不是有小轿车,至于小轿车在哪儿,不care。这就需要网络网络具有平移不变性。我们都知道,卷积本身就具有平移不变性,而pooling可以进一步增强网络的这一特性,因为pooling本身就是一个模糊位置的过程。所以pooling对于传统DCNN可以说非常nice了。
再来说语义分割。语义分割是一个end-to-end的问题,需要对每个像素进行精确的分类,对像素的位置很敏感,是个精细活儿。这就很尴尬了,pooling是一个不断丢失位置信息的过程,而语义分割又需要这些信息,矛盾就产生了。没办法,只好去掉pooling喽。全去掉行不行,理论上是可行的,实际使用嘛,一来显卡没那么大的内存,二来费时间。所以只去掉了两层。
(PS:在DeepLab V1原文中,作者还指出一个问题,使用太多的pooling,特征层尺寸太小,包含的特征太稀疏了,不利于语义分割。)
去了两个pooling,感受野又不够了怎么办?没关系,把atrous convolution借来用一下,这也是对VGG16的最后一个修改。atrous convolution人称空洞卷积,相比于传统卷积,可以在不增加计算量的情况下扩大感受野,如下图: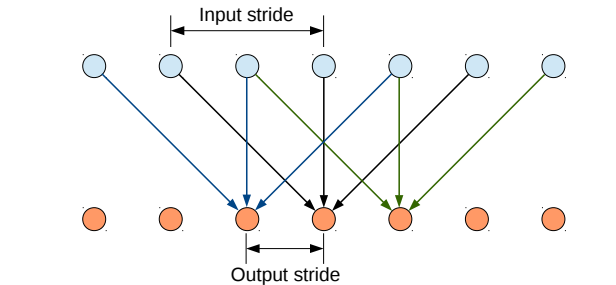
空洞卷积与传统卷积的区别在于,传统卷积是三连抽,感受野是3,如果是input_stride=2的空洞卷积是隔着抽,感受野一下扩大到了5(rate=2),相当于两个传统卷积的感受野,通过调整rate可以自由选择感受野,感受野的问题就解决了。
另外,论文指出空洞卷积还可以增加特征的密度。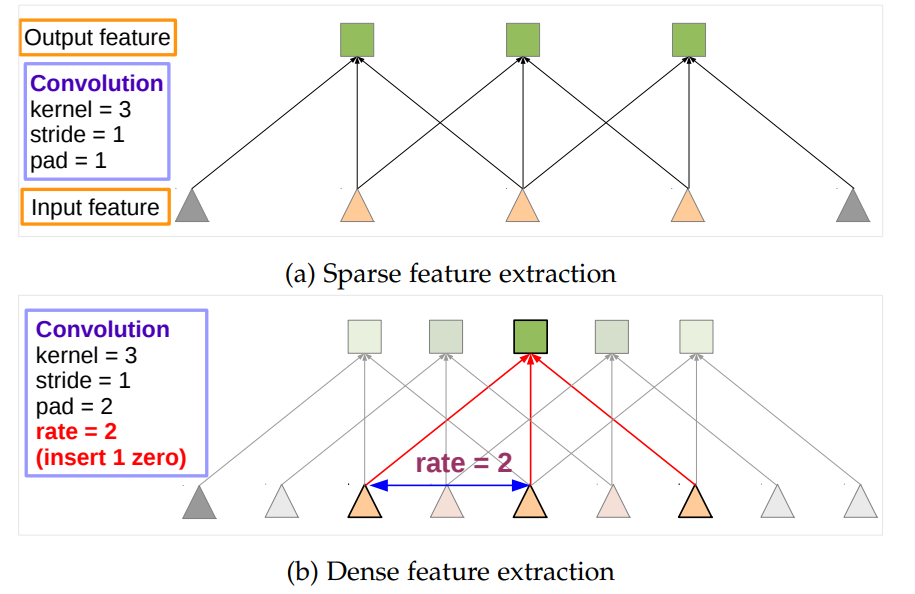
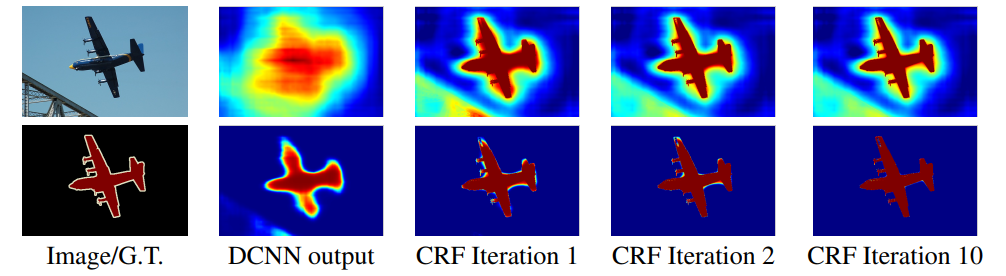
DeepLab V1的另一个贡献是使用条件随机场CRF提高分类精度。效果如下图,可以看到提升是非常明显的。
之前的论文中提到:更深的CNN可以得到更加准确的分类结果,但是定位精度会更低。解决这个问题有2种主要的方法:
- 将low level和high level的feature map进行融合,FCN就是这样做的。
- 引入super-pixel representation,用low level segmentation method来进行定位任务。
DeepLab v1中中使用全连接的条件随机场方法来对定位做finetune,这比当前的方法都要更好。
DeepLab v1中也尝试使用了多尺度预测,来提高边界定位精度:将输入图像通过2层的感知机,与前四层的pooling layer输出进行concatenate,再输入到softmax激活函数中,相当于softmax的输入channel是640。但是这种方式增加了参数量和存储空间,而且性能比不上CRF。
DeepLab v2
文章总结起来就是:空洞卷积+全连接CRF+ASPP模块, 主干网络从预训练的VGG变成了ResNet,是DeepLab v1的加强版本。
DCNNs中语义分割存在三个挑战:
- 连续下采样和池化操作,导致最后特征图分辨率低。
- 图像中存在多尺度的物体(相比V1而言提出的新的挑战)
- 空间不变性导致细节信息丢失
应对策略:
- 移除部分池化操作,使用空洞卷积。控制特征图的分辨率,保证较大感受野,得到较多的上下文信息,而不增加参数量
- 利用不同膨胀率的空洞卷积融合多尺度信息—atrous spatial pyramid pooling(ASPP)(新的创新点)。以多尺度的信息得到更精确的分割结果。ASPP并行的采用多个采样率的空洞卷积层来探测,以多个比例捕捉对象以及图像上下文。
- 全连接CRF。通过组合DCNN和概率图模型(CRF),改进分割边界结果。在DCNN中最大池化和下采样组合实现可平移不变性,但这对精度是有影响的。通过将最终的DCNN层响应与全连接的CRF结合来克服这个问题。
提取密集特征的两种方式:
- 上采样
- 空洞卷积
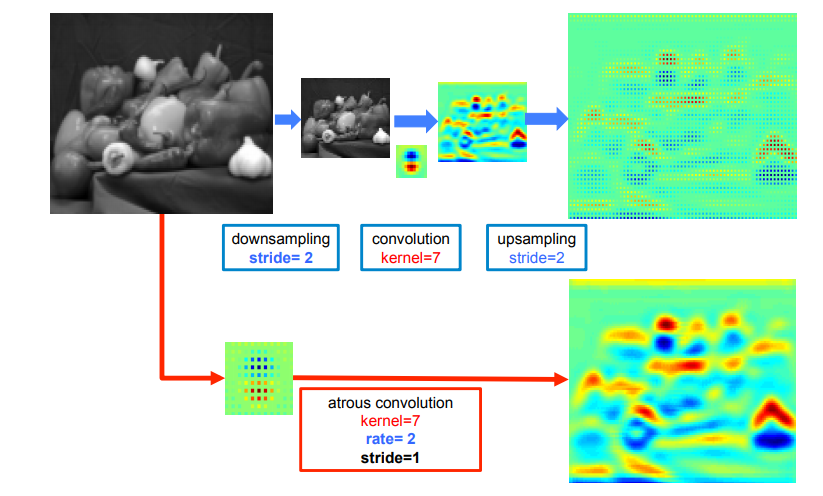
- U型操作:首先下采样将分辨率降低2倍 → 做卷积 → 上采样得到结果。本质上这只是在原图片面积的1/4的内容上做卷积响应。
- 空洞卷积:如果我们将全分辨率图像做空洞卷积(采样率为2,核大小与上面卷积核相同),直接得到结果。这样可以计算出整张图像的响应,效果更加平滑,特征更加密集。
ASPP
多尺度主要是为了解决目标在图像中表现为不同大小时仍能够有很好的分割结果,比如同样的物体,在近处拍摄时物体显得大,远处拍摄时显得小。并行采用多个采样率的空洞卷积提取特征,再将特征进行融合,该结构称为空洞空间金字塔池化(atrous spatial pyramid pooling)。如下图所示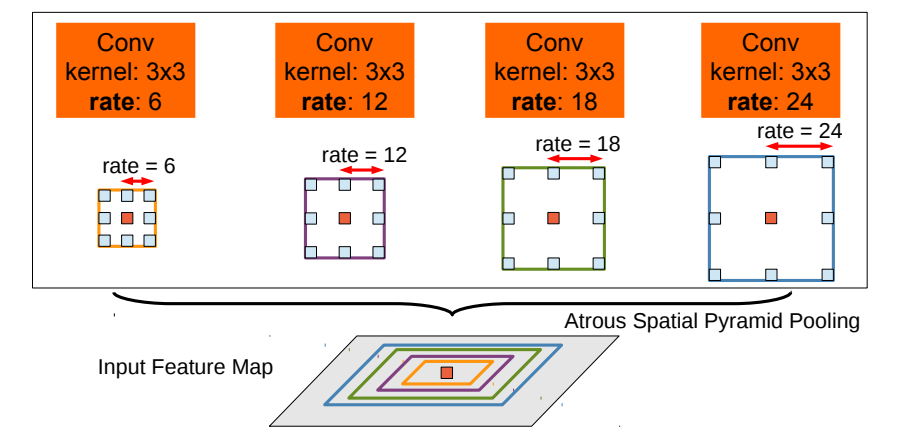
至于ASPP如何融合到VGG16中,将VGG16的conv6,换成不同rate的空洞卷积,再跟上conv7,8,最后做个大融合(对应相加或1*1卷积)就OK了。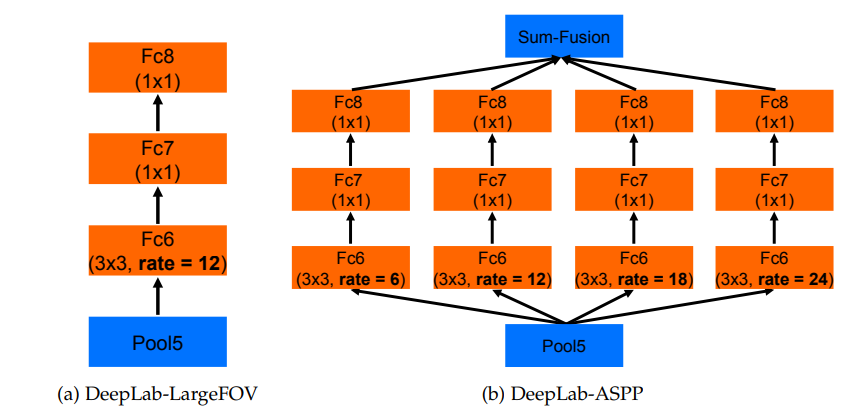
CRF
crf同deeplab v1
DeepLab v3
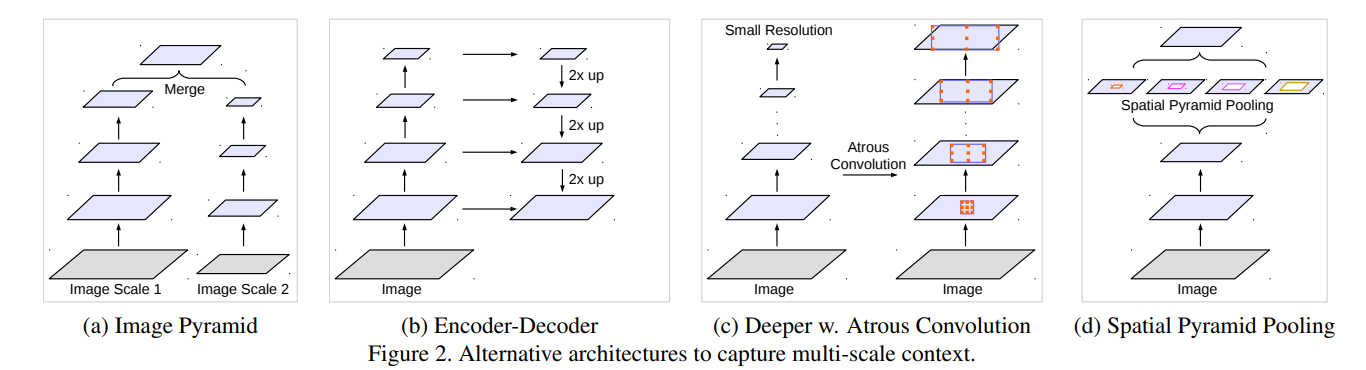
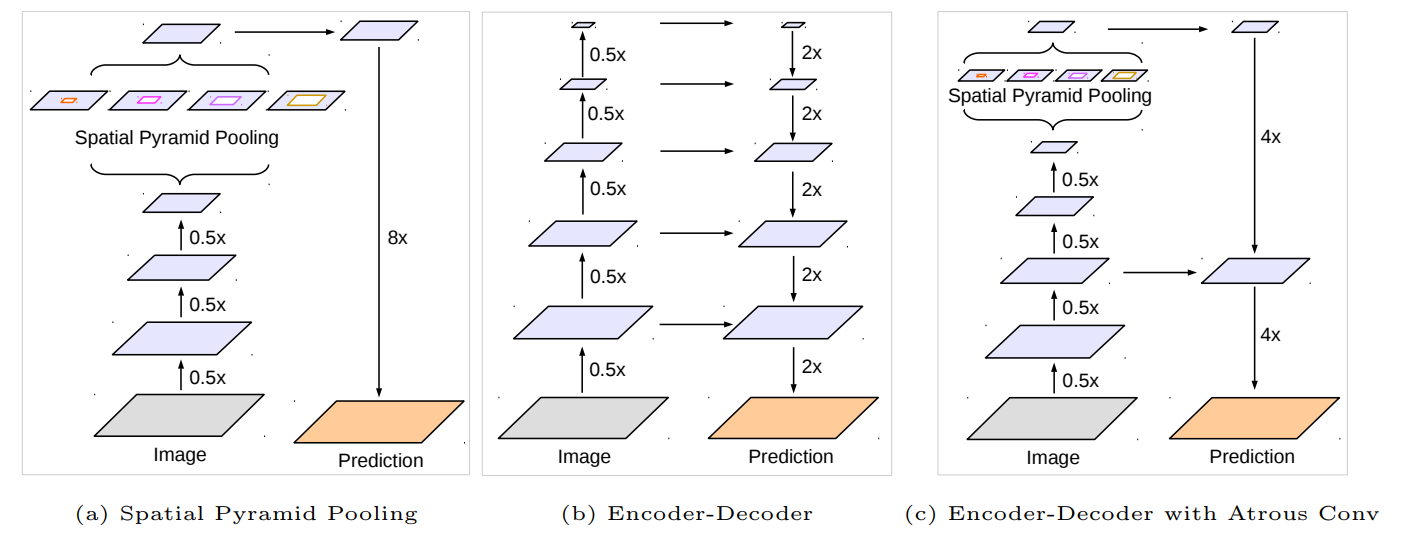
在文章开头提出几种常见的捕获multi-scale context的方法。
- 图像金字塔。输入图像进行尺度变换得到不同分辨率input,然后将所有尺度的图像放入CNN中得到不同尺度的分割结果,最后将不同分辨率的分割结果融合得到原始分辨率的分割结果,类似的方法为DeepMedic;
- 编码-解码结构。FCN和UNet等结构;
- 本文提出的串联结构。
- 本文提出的并联结构,Deeplab v3结构。
空洞卷积的串行结构
空洞卷积的串行结构会使网络加深,对应论文Sec 3.2。
使用multi-grid的方法,修改了resnet的block4~block7,使得他们的output_stride都是16,这样就可以保证空间位置信息不会损失太严重,而且论文中也发现如果一直进行下采样,将整体信息聚合到非常小的特征图上,会降低语义分割结果的准确度,如图(a)所示。加入atrous convolution的级联模块如下,主要是使用了不同rate的atrous convolution进行操作,增大filter的感受野。
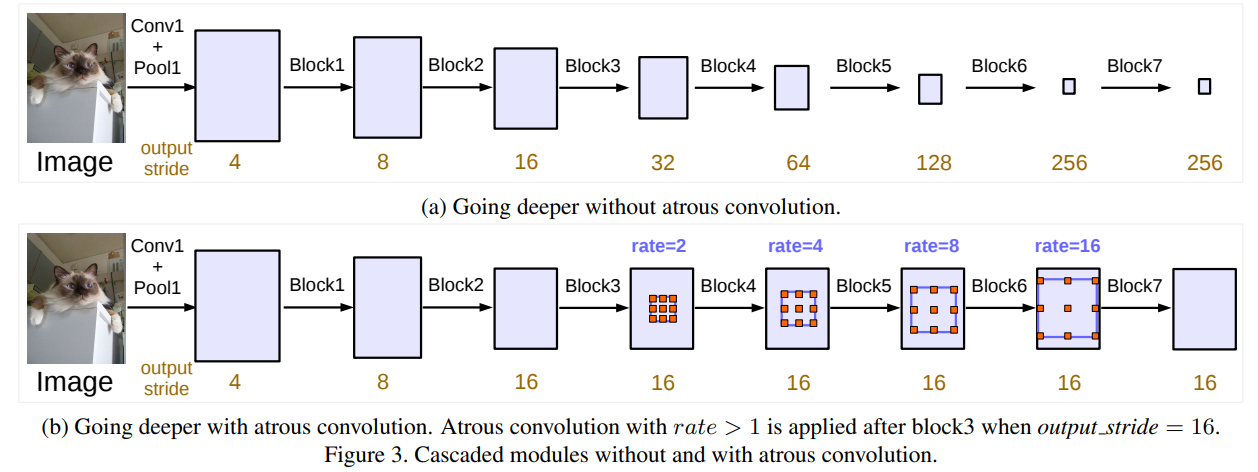
受到了采用不同大小网格层次结构的多重网格方法的启发,我们提出的模型在block4和block7中采用了不同的空洞率。
特别的,我们定义 Multi_Grid =$[r_1,r_2, r_3]$ 为block4到block7内三个卷积层的unit rates。卷积层的最终空洞率等于unit rate和corresponding rate的乘积。例如,当output_stride = 16,Multi_Grid = (1, 2, 4),block4中的三个卷积的rates = 2×(1, 2, 4) = (2, 4, 8) 。
但是实验表明,相比并行结构,这种串行的结构并不能得到一个很好的结果
空洞卷积的并行结构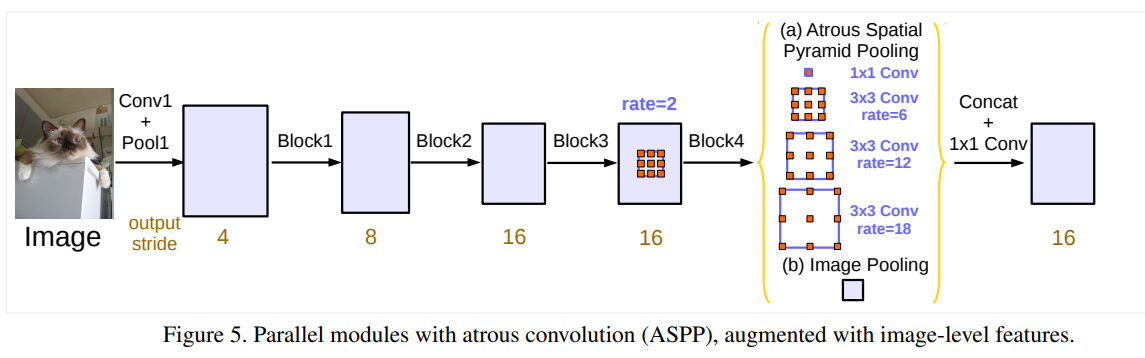
在并行结构中,改进内容包括:
- 在ASPP中加入BN层。
- 当采样率变大,图像边界响应无法捕捉远距离信息,导致卷积核的有效权重变小。只有中心的权重是有效的,3×3退化为1×1卷积核。为了解决该问题需要整合全局上下文信息,对最后的feature map采用全局池化,并经过256个1×1的卷积核+BN,然后双线性插值到所需空间维度。
最终并行结构包含
- ASPP:一个1×1的卷积和三个3×3、rates=(6,12,18)、output_stride=16的空洞卷积(256+BN)。
- 图像级特征。将特征做全局平均池化,后卷积,再上采样。
ASPP中不同rates的空洞卷积通过控制不同的padding输出相同的尺寸,图像级特征中上采样后与ASPP尺寸一致。所有分支的结果被拼接起来并经过1×1的卷积(256+BN),最后经过1×1卷积生成分割结果。
DeepLab v3+
改进:
- BackBone:Xception
- Encoder-Decoder Structure
由于BackBone可以随意替换,Xception以后会讲,并且都2121年了,有很多更强更快的BackBone可供使用,EfficientNet0~7等等。
DeepLabV1、2、3都是backbone(or ASPP)输出的结果直接双线性上采样到原始分辨率,非常简单粗暴的方法,如下图中的(a)。DeepLab v3+吸取Encoder-Deconder的结构(图中的(b)为编码器-解码器结构),增加了一个浅层到输出的skip层,如下图中的(c)。
完整的DeepLab v3+的网络结构:
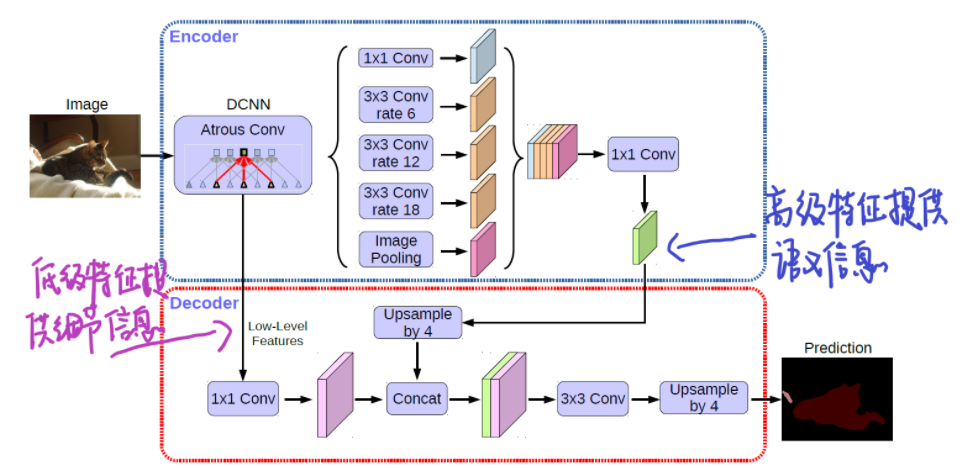
- encoder输出的feature的output_stride=16,经过双线性上采样4倍得到$F_A$,$F_A$ 的 $output \ stride=4$,
- 再取encoder中对应着相同分辨率(即$output \ stride=4$)的特征层,经过 $1×1$ 卷积降通道,此时输出的feature记为$F_B$。这里为什么要经过 $1×1$ 卷积降通道,是因为此分辨率的特征通道较多(256或512),而 $F_A$ 输出只有256,故降通道值$48$,保持比 $F_A$ 通道数,利于模型学习。
- 将 $F_A$ 和 $F_B$ 做concat,再经过一个 $3 × 3$ 卷积细化feature,最终再双线性上采样4倍得到预测结果。
在实验部分展示了 $output \ stride=16$ 是在速度和精度上最佳的平衡点,使用 $output \ stride=8$ 能够进一步提升精度,伴随着是更大的计算消耗。
总结
DeepLab v1:空洞卷积+CRF
- 减少下采样次数,尽可能的保留空间位置信息;
- 使用空洞卷积,扩大感受野,获取更多的上下文信息;
- 采用完全连接的条件随机场(CRF)这种后处理方式,提高模型捕获细节的能力。
DeepLab v2:空洞卷积+ASPP+CRF
- 在DeepLab v1的基础上提出了图像多尺度的问题,并提出ASPP模块来捕捉图像多个尺度的上下文信息。
- 仍然使用CRF后处理方式,处理边缘细节信息。
DeepLab v3:
- 改进了ASPP模块:加入了BN层,
- 探讨了ASPP模块的构建方式:并行的方式精度更好。
- 由于大采样率的空洞卷积的权重变小,只有中心权重起作用,退化成$1\times 1$卷积。所以将图像级特征和ASPP特征进行融合。
DeepLab v3+: deeplabv3 + encoder-decoder
- 使用了encoder-decoder(高层特征提供语义,decoder逐步回复边界信息):提升了分割效果的同时,关注了边界的信息
- encoder结构中:采用Xception做为 BackBone,并将深度可分离卷积(depthwise deparable conv)应用在了ASPP 和 encoder 模块中,使网络更快。
DeepLab v3+ 代码
- 主干网络采用ResNet
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163import math
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, dilation=1, downsample=None, BatchNorm=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = BatchNorm(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
dilation=dilation, padding=dilation, bias=False)
self.bn2 = BatchNorm(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = BatchNorm(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
self.dilation = dilation
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, output_stride, BatchNorm, pretrained=True):
self.inplanes = 64
super(ResNet, self).__init__()
blocks = [1, 2, 4]
if output_stride == 16:
strides = [1, 2, 2, 1]
dilations = [1, 1, 1, 2]
elif output_stride == 8:
strides = [1, 2, 1, 1]
dilations = [1, 1, 2, 4]
else:
raise NotImplementedError
# Modules
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = BatchNorm(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], stride=strides[0], dilation=dilations[0], BatchNorm=BatchNorm)
self.layer2 = self._make_layer(block, 128, layers[1], stride=strides[1], dilation=dilations[1], BatchNorm=BatchNorm)
self.layer3 = self._make_layer(block, 256, layers[2], stride=strides[2], dilation=dilations[2], BatchNorm=BatchNorm)
self.layer4 = self._make_MG_unit(block, 512, blocks=blocks, stride=strides[3], dilation=dilations[3], BatchNorm=BatchNorm)
# self.layer4 = self._make_layer(block, 512, layers[3], stride=strides[3], dilation=dilations[3], BatchNorm=BatchNorm)
self._init_weight()
if pretrained:
self._load_pretrained_model()
def _make_layer(self, block, planes, blocks, stride=1, dilation=1, BatchNorm=None):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
BatchNorm(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, dilation, downsample, BatchNorm))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, dilation=dilation, BatchNorm=BatchNorm))
return nn.Sequential(*layers)
def _make_MG_unit(self, block, planes, blocks, stride=1, dilation=1, BatchNorm=None):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
BatchNorm(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, dilation=blocks[0]*dilation,
downsample=downsample, BatchNorm=BatchNorm))
self.inplanes = planes * block.expansion
for i in range(1, len(blocks)):
layers.append(block(self.inplanes, planes, stride=1,
dilation=blocks[i]*dilation, BatchNorm=BatchNorm))
return nn.Sequential(*layers)
def forward(self, input):
x = self.conv1(input)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
low_level_feat = x
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return x, low_level_feat
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
# elif isinstance(m, SynchronizedBatchNorm2d):
# m.weight.data.fill_(1)
# m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _load_pretrained_model(self):
pretrain_dict = model_zoo.load_url('https://download.pytorch.org/models/resnet101-5d3b4d8f.pth')
model_dict = {}
state_dict = self.state_dict()
for k, v in pretrain_dict.items():
if k in state_dict:
model_dict[k] = v
state_dict.update(model_dict)
self.load_state_dict(state_dict)
def ResNet101(output_stride=16, BatchNorm=nn.BatchNorm2d, pretrained=False):
"""Constructs a ResNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 23, 3], output_stride, BatchNorm, pretrained=pretrained)
return model
if __name__ == "__main__":
import torch
model = ResNet101(BatchNorm=nn.BatchNorm2d, pretrained=True, output_stride=8)
input = torch.rand(1, 3, 512, 512)
output, low_level_feat = model(input)
print(output.size())
print(low_level_feat.size()) - DeepLab v3+
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129import torch
import torch.nn as nn
from PIL import Image
from IPython import display
from torch.nn import functional as F
import numpy as np
import math
from resnet import ResNet101
net = ResNet101()
### ASPP
class _ASPPModule(nn.Module):
def __init__(self, inplanes, planes, kernel_size, padding, dilation):
super(_ASPPModule, self).__init__()
self.atrous_conv = nn.Conv2d(inplanes, planes,
kernel_size=kernel_size,
padding=padding,
dilation=dilation,
stride=1,
bias=False)
self.bn = nn.BatchNorm2d(planes)
self.relu = nn.ReLU()
def forward(self, x):
x = self.atrous_conv(x)
x = self.bn(x)
return self.relu(x)
class ASPP(nn.Module):
def __init__(self):
super(ASPP, self).__init__()
inplanes = 2048 # resnet101 encoder
dilations = [1, 6, 12, 18]
self.aspp1 = _ASPPModule(inplanes, 256, 1, dilation=dilations[0], padding=0) # padding=dilation使得输出的4个特征图尺寸保持一致
self.aspp2 = _ASPPModule(inplanes, 256, 3, dilation=dilations[1], padding=dilations[1])
self.aspp3 = _ASPPModule(inplanes, 256, 3, dilation=dilations[2], padding=dilations[2])
self.aspp4 = _ASPPModule(inplanes, 256, 3, dilation=dilations[3], padding=dilations[3])
self.global_avg_pool = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(inplanes, 256, 1, stride=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU())
self.conv1 = nn.Conv2d(1280, 256, 1, bias=False)
self.bn1 = nn.BatchNorm2d(256)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
def forward(self, x):
x1 = self.aspp1(x)
x2 = self.aspp2(x)
x3 = self.aspp3(x)
x4 = self.aspp4(x)
x5 = self.global_avg_pool(x)
x5 = F.interpolate(x5, size=x4.size()[2:], mode='bilinear', align_corners=True)
x = torch.cat((x1, x2, x3, x4, x5), dim=1)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
return self.dropout(x)
### Decoder模块
class Decoder(nn.Module):
def __init__(self, num_classes):
super(Decoder, self).__init__()
low_level_inplanes = 256 #for resnet101 backbone
self.conv1 = nn.Conv2d(low_level_inplanes, 48, 1, bias=False)
self.bn1 = nn.BatchNorm2d(48)
self.relu = nn.ReLU()
self.last_conv = nn.Sequential(nn.Conv2d(304, 256, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Dropout(0.1),
nn.Conv2d(256, num_classes, kernel_size=1, stride=1))
def forward(self, x, low_level_feat):
low_level_feat = self.conv1(low_level_feat)
low_level_feat = self.bn1(low_level_feat)
low_level_feat = self.relu(low_level_feat)
x = F.interpolate(x, size=low_level_feat.size()[2:], mode='bilinear', align_corners=True)
x = torch.cat((x, low_level_feat), dim=1)
x = self.last_conv(x)
return x
### DeepLab v3+
class DeepLabv3p(nn.Module):
def __init__(self, num_classes=2):
super(DeepLabv3p, self).__init__()
self.backbone = ResNet101()
self.aspp = ASPP()
self.decoder = Decoder(num_classes)
def forward(self, input):
x, low_level_feat = self.backbone(input)
print('backbone----x, low_level_feat: ', x.size(), low_level_feat.size())
x = self.aspp(x)
print('ASPP output: ', x.size())
x = self.decoder(x, low_level_feat)
print('decoder output: ', x.size())
x = F.interpolate(x, size=input.size()[2:], mode='bilinear', align_corners=True)
return x
### 测试代码
deeplabv3p = DeepLabv3p()
for k,v in net.named_parameters():
print(k)
image = torch.rand((4, 3, 128, 128))
mask = net(image)
mask.size()
参考
- https://arxiv.org/abs/1412.7062v2
- http://arxiv.org/abs/1606.00915
- https://arxiv.org/abs/1706.05587
- https://arxiv.org/abs/1802.02611
- https://blog.csdn.net/fanxuelian/article/details/85145558
- https://zhuanlan.zhihu.com/p/38474698
- https://blog.csdn.net/Dlyldxwl/article/details/81148810
- https://www.dazhuanlan.com/2020/04/19/5e9bc2dbb7640/
- https://zhuanlan.zhihu.com/p/196491750
- https://www.cnblogs.com/vincent1997/p/10889430.html
- https://zhuanlan.zhihu.com/p/75333140
- https://zhuanlan.zhihu.com/p/139187977
- https://blog.csdn.net/fanxuelian/article/details/85145558
- https://blog.csdn.net/u011974639/article/details/79148719
- https://blog.csdn.net/u011974639/article/details/79144773
- https://blog.csdn.net/u011974639/article/details/79518175
- https://blog.csdn.net/u011974639/article/details/79134409
- https://www.jianshu.com/p/295dcc4008b4
- https://zhuanlan.zhihu.com/p/34929725
- https://blog.csdn.net/magic_ll/article/details/109731491
- https://github.com/DarrenmondZhang/U_Net-DeepLabV3_Plus